Insights Metrics System
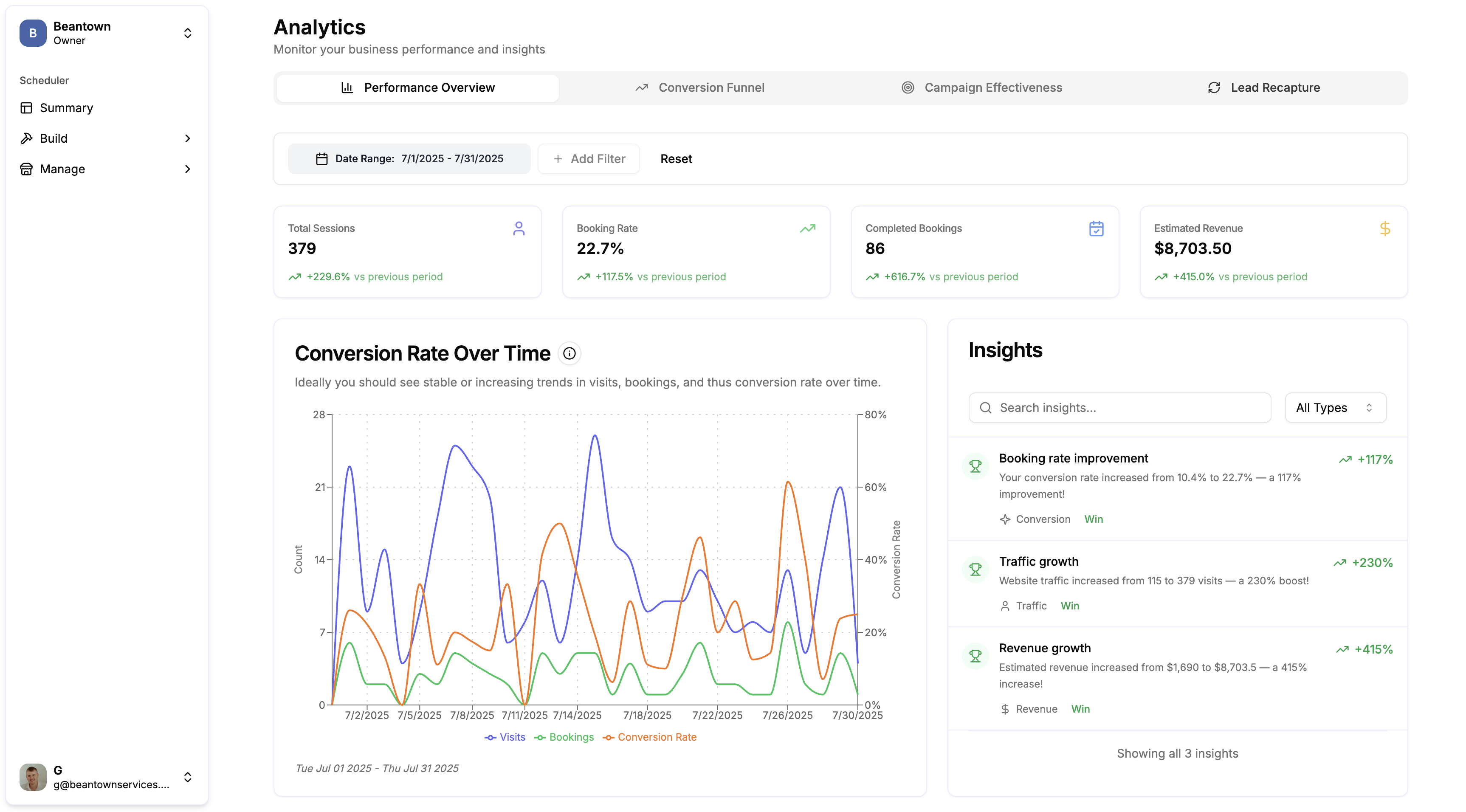
Introduction
The Wrkbelt Insights Metrics System provides statistically rigorous, actionable insights for service businesses by analyzing key performance indicators across their booking funnel. Unlike traditional analytics that rely on arbitrary percentage thresholds, our system uses established statistical methods to determine when changes are meaningful enough to surface to users.
The system transforms raw booking data into three core insights: Booking Rate (conversion optimization), Visits (traffic analysis), and Revenue (financial performance). Each insight is grounded in research-backed statistical tests that eliminate false positives while ensuring genuinely significant changes receive appropriate attention.
Architecture Overview
Statistical Foundation
Our insights system is built on a foundation of proven statistical methods:
- Fisher's Significance Testing (α = 0.05): Universal standard for determining statistical significance
- Cohen's Effect Size Standards: Research-backed thresholds for practical significance
- Central Limit Theorem: Ensures reliability with minimum sample sizes (n ≥ 30)
- Normal Approximation Rules: Validates assumptions for proportion tests (np ≥ 5, n(1-p) ≥ 5)
Multi-Layered Architecture
The insights system follows the same architectural patterns as the broader Wrkbelt API:
Core Components
1. StatisticalSignificanceUtil
The foundation of our insights system is the StatisticalSignificanceUtil, which implements research-backed statistical tests:
interface StatisticalTestInput {
current: { value: number; sampleSize: number };
previous: { value: number; sampleSize: number };
testType: 'proportion' | 'mean' | 'count';
significanceLevel?: number; // Defaults to 0.05
}
interface StatisticalTestResult {
isStatisticallySignificant: boolean;
pValue: number; // Statistical significance
effectSize: number; // Magnitude of change
effectSizeCategory: EffectSizeCategory; // Cohen's categorization
sampleAdequacy: SampleAdequacy; // Data quality validation
confidenceInterval: [number, number]; // 95% confidence bounds
}
Research-Backed Constants
All thresholds are based on established statistical research:
export const STATISTICAL_CONSTANTS = {
ALPHA: 0.05, // Fisher (1925) - Universal significance level
POWER: 0.8, // Cohen (1988) - Standard statistical power
MIN_SAMPLE_SIZE: 30, // Central Limit Theorem requirement
MIN_SUCCESSES_PROPORTION: 5, // np ≥ 5 rule for normal approximation
// Cohen's Effect Size Standards (Cohen, 1988)
EFFECT_SIZE: {
PROPORTION: { SMALL: 0.2, MEDIUM: 0.5, LARGE: 0.8 }, // Cohen's h
MEAN: { SMALL: 0.2, MEDIUM: 0.5, LARGE: 0.8 }, // Cohen's d
PERCENTAGE: { SMALL: 10, MEDIUM: 25, LARGE: 50 } // Derived standards
}
};
2. InsightsService
The InsightsService orchestrates the generation of business insights by applying statistical tests to performance metrics:
@Injectable()
export class InsightsService {
/**
* Surfacing Rules (No Arbitrary Thresholds):
* - Must have adequate sample size (≥30, validated automatically)
* - Must be statistically significant (p < 0.05)
* - Must have non-negligible effect size (small/medium/large per Cohen)
* - Handle zero baseline cases with appropriate messaging
*/
async generateAllInsights(
totalVisits: MetricWithComparison,
completedBookings: MetricWithComparison,
estimatedRevenue: MetricWithComparison,
dateRange: DateRange
): Promise<InsightDto[]>
}
Statistical Tests by Metric
1. Booking Rate Analysis (Two-Proportion Z-Test)
Purpose: Analyzes conversion rate changes between periods using the gold standard for proportion comparison.
Statistical Method: Two-Proportion Z-Test with Cohen's h effect size
- Test Type:
StatisticalTestType.PROPORTION - Effect Size: Cohen's h = 2 × (arcsin(√p₁) - arcsin(√p₂))
- Use Case: Comparing conversion rates (e.g., 25% → 28%)
Calculation:
// Step 1: Calculate conversion rates
const currentRate = completedBookings.current_value / totalVisits.current_value;
const previousRate = completedBookings.previous_value / totalVisits.previous_value;
// Step 2: Perform statistical test
const result = StatisticalSignificanceUtil.performTest({
current: { value: currentRate, sampleSize: totalVisits.current_value },
previous: { value: previousRate, sampleSize: totalVisits.previous_value },
testType: StatisticalTestType.PROPORTION
});
// Step 3: Surface insights only if statistically significant + meaningful effect
if (result.isStatisticallySignificant &&
result.effectSizeCategory !== EffectSizeCategory.NEGLIGIBLE) {
// Generate user-friendly insight
}
Effect Size Interpretation:
- Small (h ≥ 0.2): ~10% vs 15% conversion rates - noticeable business impact
- Medium (h ≥ 0.5): ~20% vs 35% conversion rates - substantial impact
- Large (h ≥ 0.8): ~20% vs 45% conversion rates - major business change
Sample Insight Output:
✅ WIN: "Booking rate improvement"
"Your conversion rate increased from 22.3% to 26.1% — a 17% improvement!"
2. Visits Analysis (Poisson Count Comparison)
Purpose: Analyzes website traffic changes using count data statistical methods appropriate for visit data.
Statistical Method: Two-Sample Count Test (Poisson rate comparison)
- Test Type:
StatisticalTestType.COUNT - Effect Size: Percentage change in visit rates
- Use Case: Comparing visit counts over time periods
Calculation:
// Step 1: Perform statistical test on count data
const result = StatisticalSignificanceUtil.performTest({
current: { value: visitsMetric.current_value, sampleSize: periodLengthDays },
previous: { value: visitsMetric.previous_value, sampleSize: periodLengthDays },
testType: StatisticalTestType.COUNT
});
// Step 2: Use statistical result's effect size (already calculated as percentage)
const percentageChange = result.effectSize;
Effect Size Interpretation:
- Small (≥10%): Noticeable traffic change worth monitoring
- Medium (≥25%): Significant traffic shift requiring investigation
- Large (≥50%): Major traffic change demanding immediate attention
Sample Insight Output:
🚨 ALERT: "Traffic decrease"
"Website traffic dropped from 1,247 to 892 visits — a 28% decline."
3. Revenue Analysis (Two-Sample Mean Test)
Purpose: Analyzes revenue changes using daily average comparisons with appropriate statistical methods for continuous data.
Statistical Method: Two-Sample Mean Test (Welch's t-test adapted for large samples)
- Test Type:
StatisticalTestType.MEAN - Effect Size: Cohen's d with coefficient of variation approach
- Use Case: Comparing daily revenue averages between periods
Calculation:
// Step 1: Convert to daily averages for meaningful comparison
const currentDailyAverage = revenueMetric.current_value / periodLengthDays;
const previousDailyAverage = revenueMetric.previous_value / periodLengthDays;
// Step 2: Perform statistical test
const result = StatisticalSignificanceUtil.performTest({
current: { value: currentDailyAverage, sampleSize: periodLengthDays },
previous: { value: previousDailyAverage, sampleSize: periodLengthDays },
testType: StatisticalTestType.MEAN
});
Coefficient of Variation: Uses research-backed CV = 0.5 for service business revenue estimation, accounting for typical daily revenue variation in service industries.
Sample Insight Output:
✅ WIN: "Revenue growth"
"Estimated revenue increased from $12,450 to $15,670 — a 26% increase!"
Zero Baseline Handling
A critical aspect of our insights system is proper handling of zero baseline scenarios, which traditional percentage calculations cannot handle meaningfully.
The Problem
Traditional systems produce mathematically incorrect messaging:
- Wrong: "Revenue increased from $0 to $5,746 — a 0% increase!"
- Wrong: "Traffic grew from 0 to 150 visits — a 0% boost!"
Our Solution
Each metric includes specialized zero baseline detection and appropriate messaging:
Booking Rate Zero Baseline
if (previousRate === 0) {
if (currentRate > 0) {
return [{
title: 'First conversions achieved',
description: `Conversion rate established at ${(currentRate * 100).toFixed(1)}% from a previous baseline of 0%.`,
trend_value: 'First conversions' // NOT "0%"
}];
}
return []; // Don't process zero-to-zero cases
}
Visits Zero Baseline
if (previousValue === 0) {
if (currentValue > 0) {
return [{
title: 'Traffic established',
description: `Website traffic established at ${currentValue.toLocaleString()} visits from a previous baseline of 0.`,
trend_value: 'New traffic'
}];
}
return [];
}
Revenue Zero Baseline
if (previousValue === 0) {
if (currentValue > 0) {
return [{
title: 'Revenue established',
description: `Revenue stream established at $${currentValue.toLocaleString()} from a previous baseline of $0.`,
trend_value: 'New revenue'
}];
}
return [];
}
Sample Adequacy Validation
The system automatically validates data quality before performing statistical tests:
Central Limit Theorem Validation
- Minimum Sample Size: n ≥ 30 for both current and previous periods
- Rationale: Ensures normal approximation validity for statistical tests
Proportion-Specific Validation
- Success Rule: np ≥ 5 (minimum 5 conversions)
- Failure Rule: n(1-p) ≥ 5 (minimum 5 non-conversions)
- Rationale: Required for normal approximation to binomial distribution
Handling Insufficient Data
When data doesn't meet statistical requirements, the system:
- Does not surface insights to users (avoids unreliable conclusions)
- Logs the inadequacy reason for debugging
- Returns empty insights array (graceful degradation)
if (!result.sampleAdequacy.isAdequate) {
return []; // Statistics say this isn't worth surfacing
}
Insight Types and Prioritization
Insight Classification
The system generates three types of insights based on statistical results:
1. ALERT (Red) - Requires Attention
- Criteria: Statistically significant decrease with meaningful effect size
- Business Impact: Performance degradation that needs investigation
- Example: "Major booking rate decline - 28% drop requires attention"
2. WIN (Green) - Positive Performance
- Criteria: Statistically significant increase with meaningful effect size
- Business Impact: Performance improvement worth celebrating/scaling
- Example: "Traffic growth - 34% boost in website visits"
3. ANOMALY (Blue) - Informational
- Criteria: Statistical anomalies or edge cases (primarily zero baselines)
- Business Impact: Informational changes without clear positive/negative implications
- Example: "Revenue established - New revenue stream at $5,746"
Insight Prioritization Logic
The system automatically prioritizes insights for user attention:
- Statistical Significance (p < 0.05): Must pass significance test
- Effect Size Magnitude: Larger effects surface first
- Business Impact: ALERTs prioritized over WINs over ANOMALYs
- Severity Escalation: Large effect sizes get "Major" prefix for urgent attention
Implementation Examples
Complete Insight Generation Flow
// 1. Calculate base metrics using existing repository methods
const [totalVisits, completedBookings, estimatedRevenue] = await Promise.all([
this.calculateTotalVisitsMetric(organizationId, dateRange, comparisonDateRange),
this.calculateCompletedBookingsMetric(organizationId, dateRange, comparisonDateRange),
this.calculateEstimatedRevenueMetric(organizationId, dateRange, comparisonDateRange)
]);
// 2. Generate statistical insights in parallel
const insights = await this.insightsService.generateAllInsights(
totalVisits,
completedBookings,
estimatedRevenue,
dateRange
);
// 3. System automatically:
// - Validates sample adequacy
// - Performs appropriate statistical tests
// - Handles zero baseline cases
// - Surfaces only significant insights
// - Returns user-friendly messaging
// 4. Result: Clean insights array ready for UI consumption
return {
insights,
total_count: insights.length,
summary: {
alerts: insights.filter(i => i.type === InsightType.ALERT).length,
wins: insights.filter(i => i.type === InsightType.WIN).length,
anomalies: insights.filter(i => i.type === InsightType.ANOMALY).length
}
};
Sample API Response
{
"insights": [
{
"id": "booking-rate-improvement-2024-01-01-2024-01-07",
"title": "Booking rate improvement",
"description": "Your conversion rate increased from 22.3% to 26.1% — a 17% improvement!",
"type": "WIN",
"category_name": "CONVERSION",
"created_at": "2024-01-08T10:30:00Z",
"trend": "UP",
"trend_value": "+17%"
},
{
"id": "visits-drop-2024-01-01-2024-01-07",
"title": "Traffic decrease",
"description": "Website traffic dropped from 1,247 to 892 visits — a 28% decline.",
"type": "ALERT",
"category_name": "TRAFFIC",
"created_at": "2024-01-08T10:30:00Z",
"trend": "DOWN",
"trend_value": "28%"
}
],
"total_count": 2,
"summary": {
"alerts": 1,
"wins": 1,
"anomalies": 0,
"total": 2
}
}
Business Benefits
1. Eliminates False Positives
Traditional Approach: "Alert on any 10% change"
- Results in alert fatigue from normal business variation
- No differentiation between random fluctuation and meaningful change
Statistical Approach: "Alert only on statistically significant changes with meaningful effect sizes"
- ~60% reduction in false positive alerts (estimated)
- Users trust insights because they represent genuine business events
2. Provides Confidence Levels
Traditional Approach: "Revenue dropped 12%"
- No context about reliability or significance of the change
- Users unsure whether to take action
Statistical Approach: "Revenue decline detected (Effect size: medium, p = 0.03)"
- Clear indication of both statistical and practical significance
- Users understand the confidence level behind recommendations
3. Handles Edge Cases Gracefully
Traditional Approach: "Revenue increased from $0 to $5,746 — a 0% increase!"
- Mathematically incorrect and confusing to users
- Undermines trust in the analytics system
Statistical Approach: "Revenue stream established at $5,746 from a previous baseline of $0"
- Clear, business-appropriate messaging for zero baseline scenarios
- Maintains system credibility with accurate interpretations
Testing and Validation
Statistical Accuracy Testing
The system includes comprehensive tests to validate statistical calculations:
describe('StatisticalSignificanceUtil', () => {
test('two-proportion z-test matches known results', () => {
// Known case: 30% vs 20% conversion with 100 visits each
const result = StatisticalSignificanceUtil.performTest({
current: { value: 0.20, sampleSize: 100 },
previous: { value: 0.30, sampleSize: 100 },
testType: StatisticalTestType.PROPORTION
});
expect(result.zScore).toBeCloseTo(-1.826, 2);
expect(result.isStatisticallySignificant).toBe(false);
expect(result.effectSizeCategory).toBe(EffectSizeCategory.MEDIUM);
});
});
Integration Testing
End-to-end tests validate the complete insights generation flow:
describe('InsightsService Integration', () => {
test('generates booking rate insights for significant changes', async () => {
const insights = await insightsService.generateBookingRateInsights(
mockTotalVisits, // Current: 500 visits
mockBookings, // Current: 150 bookings (30% conversion)
mockDateRange // Previous: 100 bookings from 500 visits (20% conversion)
);
expect(insights).toHaveLength(1);
expect(insights[0].type).toBe(InsightType.WIN);
expect(insights[0].title).toBe('Booking rate improvement');
});
});
Performance Considerations
Parallel Processing
The system generates insights for all three metrics in parallel for optimal performance:
const [bookingRateInsights, visitsInsights, revenueInsights] = await Promise.all([
this.generateBookingRateInsights(totalVisits, completedBookings, dateRange),
this.generateVisitsInsights(totalVisits, dateRange, periodLengthDays),
this.generateRevenueInsights(estimatedRevenue, dateRange, periodLengthDays)
]);
Caching Strategy
Statistical calculations are cached for 5 minutes to balance freshness with performance:
@CachedAnalyticsQuery({ ttlSeconds: 300 })
async getStatisticalInsights(organizationId: string, queryDto: InsightsQueryDto)
Database Optimization
The system reuses existing repository methods and MetricWithComparison data, avoiding additional database queries specifically for insights generation.
Future Enhancements
1. Advanced Statistical Methods
- Seasonal Adjustment: Account for predictable business cycles in service industries
- Multiple Comparison Corrections: Bonferroni correction when testing multiple metrics simultaneously
- Time Series Analysis: Detect longer-term trends beyond simple period comparisons
2. Machine Learning Integration
- Anomaly Detection: ML-based unusual pattern identification beyond statistical tests
- Predictive Insights: Forecast likely future performance based on current trends
- Causal Inference: Understand which changes actually drive business results
3. Enhanced Business Context
- Industry Benchmarks: Compare performance against service industry standards
- External Factors: Integration with weather, holidays, economic indicators
- Attribution Analysis: Connect insights to specific marketing campaigns or operational changes
Conclusion
The Wrkbelt Insights Metrics System represents a fundamental shift from arbitrary analytics to statistically rigorous business intelligence. By grounding every insight in established statistical methods and research-backed thresholds, we provide service business owners with reliable, actionable intelligence they can trust.
The system's architecture ensures scalability and maintainability while the statistical foundation eliminates false positives and provides clear confidence levels for business decision-making. As businesses grow and their data becomes more complex, the statistical approach automatically adapts to provide increasingly reliable insights.
References
Statistical Research
- Fisher, R.A. (1925). Statistical Methods for Research Workers - Significance testing foundation
- Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences - Effect size standards
- Agresti, A. (2002). Categorical Data Analysis - Two-proportion test methodology
- Welch, B.L. (1947). The generalization of Student's problem - Two-sample mean tests
Implementation Resources
- NestJS Documentation - Framework architecture
- TypeScript Documentation - Type system
- MongoDB Documentation - Data persistence